研究紹介
(内容がやや古くなっています。)
研究領域は、データマイニングや機械学習分野です。主に以下の様な研究テーマに取り組んでいます。
- 離散データ構造間の類似度設計
- 高速な特徴選択アルゴリズムの開発
- 2部グラフからの知識発見
- 計算アーカイブズ学
離散データ構造間の類似度設計
文字列より複雑な木構造、順序構造、グラフ構造といった離散データ構造に関する類似度を設計し、理論的な性質を調べています。また、その成果をデータマイニングや機械学習へ応用しています。
類似度・距離設計
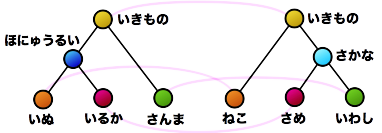
木構造は様々なアルゴリズムで重要な役割を果たし、構文木や進化系統樹、生物の糖鎖構造の表現にも用いられるデータ構造です。
2つの木構造が与えられたとき、この2つの構造はどの程度似ているのでしょうか。その度合いを評価するための指標(類似度や距離)は、一通りではありません。
もっとも粗い評価の方法は、2つの構造が完全一致しているか否かを問うものです(同型判定)。木構造の同型判定は効率のよいアルゴリズムが知られています。しかし、多少の不一致は許容して、どの程度似ているのかを評価する問題は
- いろいろな類似度や距離の定義が考えられる
- 一般には計算がとても大変(例えば、無順序木に対する(あるクラスの)木の編集距離計算問題はNP完全)
といった理由から、そう簡単ではありません。広く用いられている編集距離は、 1つの構造をもう一方の構造に書き換えるための編集操作の最小コストにより定義されます。本研究では、明確な基準もないまま乱立していた様々な木の編集距離アルゴリズムや類似度概念を整理し、その相互関係を明らかにしました。
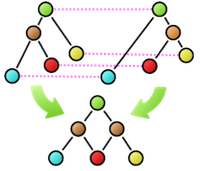
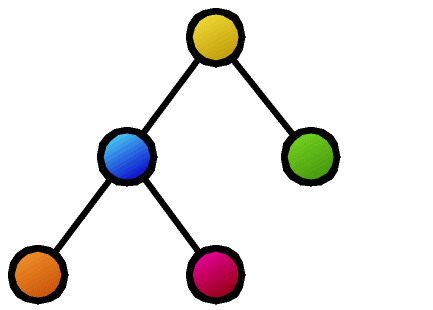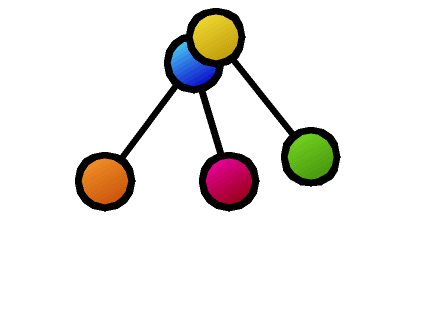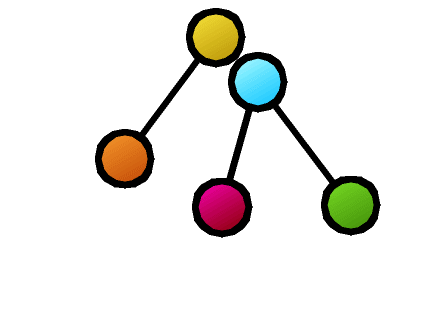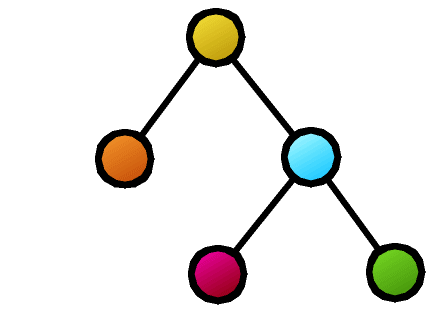
また、木の比較に関連するごく基本的な性質も意外と知られていません。たとえば、図の2つの木の類似度計算の結果、破線で結ばれたノードの対応がとれたとします。この対応したノードを重ね合わせて、各々の木の上下関係を保ったまま、新たに合成木(supertree)を作ることはできるでしょうか。この例では、赤のノードが合流点となり木構造が保てなくなってしまいます。合成後に木構造となるようなノード対応の取り方の必要十分条件は、我々の研究により、はじめて明らかになりました。
類似度・距離の設計については、主に次の2つの観点から取り組んでいます。
- 最適化問題
- 共通部分の最大化(最大共通部分木問題)や不一致部分の最小化(木の編集距離問題)として類似度・距離を設計します。メリットは、計算結果として構成的に、どの部分が似ているのかがわかることです(図では2つの木構造間をつなぐ線として表現してあります)。
- 数え上げ問題
- 共通する部分構造の数え上げ。数え上げ問題として類似度・距離を計算することのメリットは、局所的な類似性を汲み取ることができること、必ずしも構成的に計算する必要がないこと、木構造の分類学習(機械学習における木カーネル設計)にすぐに適用できることです。
これらの基礎研究を「がん由来の糖鎖構造の分類学習」や「時系列コミュニティ階層構造の分析」等に応用しています。
主な共同研究
-
学習院大学 申研究室:
- 様々な木の編集距離の一般化と、理論的な体系づけ、木カーネル設計への応用
- 離散データ構造のカーネル設計の理論
- 九州工業大学 平田研究室: 木の編集距離アルゴリズムのクラス階層と計算量の対応
- 広島市立大学 宮原研究室: 遺伝的プログラミングに基づく木構造のパターン発見
- 京都大学 山本研究室: 木の編集距離アルゴリズムと新しい木の距離指標の開発
-
東京電機大学 前田研究室:
- 伊勢型紙デジタルアーカイブ(立命館大学ARCとの共同研究)
高速な特徴選択アルゴリズムの開発
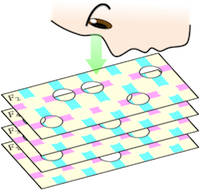
特徴選択は、膨大な属性を持つデータから目的に応じて必要な属性のみを取り出す問題です。データマイニングや機械学習では、重要な基本問題です。
本研究では、離散と連続をつなぐ面白い部分問題を含んだカテゴリカルデータの特徴選択問題に着目し、既存のアルゴリズム中で最も高性能なCWCの理論的な性質の解析と、アルゴリズムの改良、および応用に取り組んでいます。CWCは特徴選択問題を、一種の集合被覆問題として定式化し、貪欲法により特徴を抽出します(図はアルゴリズムのイメージ)。
CWCはとてもシンプルな評価指標を用いて特徴を残すか否かを決定しているにもかかわらず、様々なベンチマークによって実験的にとても高い性能を示すことがわかっています。現在、その性能の良さを理論的にも裏付けるための解析を進めています。
また、このアルゴリズムを、機械学習の前処理だけでなく、膨大なドキュメントからの高速なトピック語抽出にも応用しています。
開発したソフトウェア
- sCWC: 巨大なスパースデータに対応した高速な特徴選択器です。Scalaで実装しています。
主な共同研究
- **学習院大学 申研究室特徴選択アルゴリズムCWCは2011年に申先生によって提案されました。
公共事業入札データの分析

適正な競争入札と談合の判断基準として落札率が広く知られています。しかし、落札率を目的変数とする回帰問題を解くだけでは、必ずしも競争入札の適正性を分析できるわけではありません。
本研究では、入札に参加する業者間のつながりに着目して、その構造の時系列変化や、業者コミュニティの変化を分析しています。図は、ある地方自治体の入札業者間のつながりをネットワークとして可視化したものです。
現在、膨大な入札データに潜む業者の関係性を抽出し、分析することにより、新しい入札データ分析のための要素技術を開発中です。とくに、同じ入札に排他的に参加している業者グループを発見するための時系列ネットワーク上のコミュニティ抽出法について研究しています。
コンピューターログからのユーザー行動推定
コンピューターのログ情報、なかでも、アクティブウインドウの遷移データを用いて、ユーザーの行動推定をしています。
まず、ウインドウの遷移は背後にある仕事によって生成されると仮定し、隠れマルコフモデルを用いてログを分節化します。こうして抽象化された仕事単位を用いてユーザごとに状態遷移図を作成します。状態遷移図をグラフ構造とみなし、グラフカーネルとカーネル主成分分析により、仕事の進め方のパターンが似通ったユーザのクラスタリングをします。アイデアはシンプルですが、実際の業務とも対応した解釈容易な結果が得られます。
その他にも、ウインドウ切替の統計的な特徴を抽出し、勤怠状況を判別する分析も行っています。
インフルエンザウイルスの遺伝子変異分析
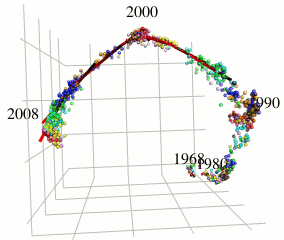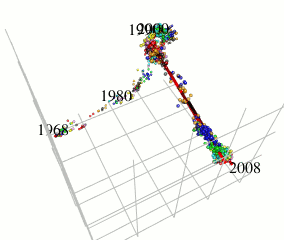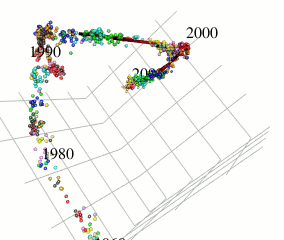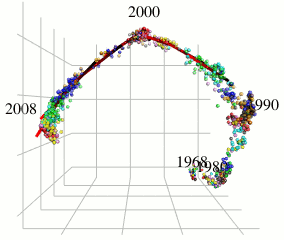
本研究では、世界的な流行を引き起こしているA型インフルエンザウイルスに着目し、そのアミノ酸配列データから抗原の連続変異モデルを構築することを目的としています。北海道大学人獣共通感染症リサーチセンターの伊藤先生らの変異予測や共変異パターン抽出に関する既存研究とは異なるアプローチを用いています。
既存研究ではインフルエンザウイルスのヘマグルルチニン遺伝子に対応するアミノ酸配列の変異をハミング距離空間内で観察することにより変異予測を行っています。これに対して、本研究ではハミング距離空間のもつ性質を保ったまま取り扱いの容易なユークリッド距離空間での計算が可能となるようなアミノ酸記号空間の(低歪み)埋め込みを用い、局所的に疎主成分分析を用いることにより、インフルエンザウイルスの進化方向のみの成分を取り出します(図参照)。本手法により、既存手法の予測性能を改善することができました。
主な共同研究
- 北海道大学 伊藤研究室: 既存のインフルエンザウイルスの遺伝子情報に関わる様々な問題設定や研究テーマを提供して頂いています。
ソーシャルメディアからの時系列トピック抽出
Twitterやブログ、ショッピングサイトの評価書込み等の時系列データから、ユーザのニーズの変遷の抽出を試みています。要素技術としては、自然言語理解分野で用いられているトピック抽出法の他に、ネットワークの階層的コミュニティ抽出法と、木の編集距離を組み合わせた方法等、様々な手法を用いています。
主な共同研究
- 千葉商科大学 橋本研究室: ブログからの東日本大震災後の被災者のニーズ変化の時系列解析等、 SNSの時系列データの分析。
絡み目不変量の高速な計算
絡み目の不変量の一つであるミルナー不変量の現実的かつ効率的な計算方法の開発を目的としています。与えられた2つの絡み目が同値であるかどうかを判定し、絡み目を分類する絡み目の「位置の問題」に関する研究は、位相幾何学の一分野である結び目理論の重要な課題の1つです。同値判定において鍵となる絡み目不変量の1つであるミルナー不変量はジョン・ミルナーよって1954年に提案されました。ミルナーによって提案されたミルナー不変量を計算するアルゴリズムは非常にシンプルなのですが、計算過程で生成される式の大きさが膨大であるため、近年まで実計算による研究は殆ど行われていませんでした。
ミルナー不変量の計算では変数列が非可換です。本研究では、非可換な変数列が文字列とみなせることに着目し、優れた高効率の文字列アルゴリズムをミルナー不変量の計算に適用することにしました。特に、九州工業大学の坂本比呂志教授らの研究グループによって研究が進められている文法圧縮アルゴリズムによりに、ミルナー不変量の効率的な計算アルゴリズムの開発を共同で進めています。
文法圧縮技術を用いると、たとえば、ミルナー不変量計算の過程で生成される長さ約300万変数の単項式(300万文字)を、約1600文字まで圧縮することができます。通常の文章を対象とした一般の圧縮とは桁違いの圧縮率です。文法圧縮アルゴリズムにより、共通計算をくくりだすことにより、少メモリーでかつ高速なミルナー不変量の計算が実現できました。
ミルナー不変量の計算ツールにより、絡み目の新たな性質の予測が期待できます。
主な共同研究
- 早稲田大学 安原研究室: 実際にミルナー不変量を用いた絡み目の研究をしている研究室です。本研究の成果を用いて絡み目の性質に関する論文が書かれました。
- 九州工業大学 坂本研究室: 坂本先生と高畠先生との共同研究により、ミルナー不変量計算のシステムを構築中です。
その他、進行中の研究
-
CRESTデータ粒子化による高速高精度な次世代マイニング技術の創出
- 共同研究: 国立情報学研究所 宇野研究室
- ソーシャルメディアデータにおける本人特定の可能性と匿名性の評価
- 共同研究: 電気通信大学 吉浦裕名誉
- プリンターログからの学生の印刷行動の推定
- Web入力システムにおける外れ値推定(企業との共同研究)